Why Legal Professionals Should Try Running AI Locally

Running your own language model sounds like something only developers or AI hobbyists would do. That’s changing fast, because if you work in legal tech, or even legal ops, it’s absolutely worth knowing what today’s local models can do.
No licence fees. No vendor lock-in. No data leaving your laptop.
All you need is a bit of curiosity and a half-decent machine.
So… why bother?
Hosted tools like ChatGPT are convenient, but they’re also opaque. You don’t control when the model changes, neither can you guarantee where your data goes and you often can’t trace what led to a particular answer.
In contrast, running a model locally gives you:
- Full control over your inputs and outputs
- Consistent results as nothing changes unless you change it
- A safer sandbox for testing AI on legal tasks
- The ability to experiment without sharing a single thing externally
Most importantly, it gives you direct experience with how models behave. Not from reading blog posts (though please read these) and not from marketing decks but from your own machine, with your own documents.
What can you actually try?
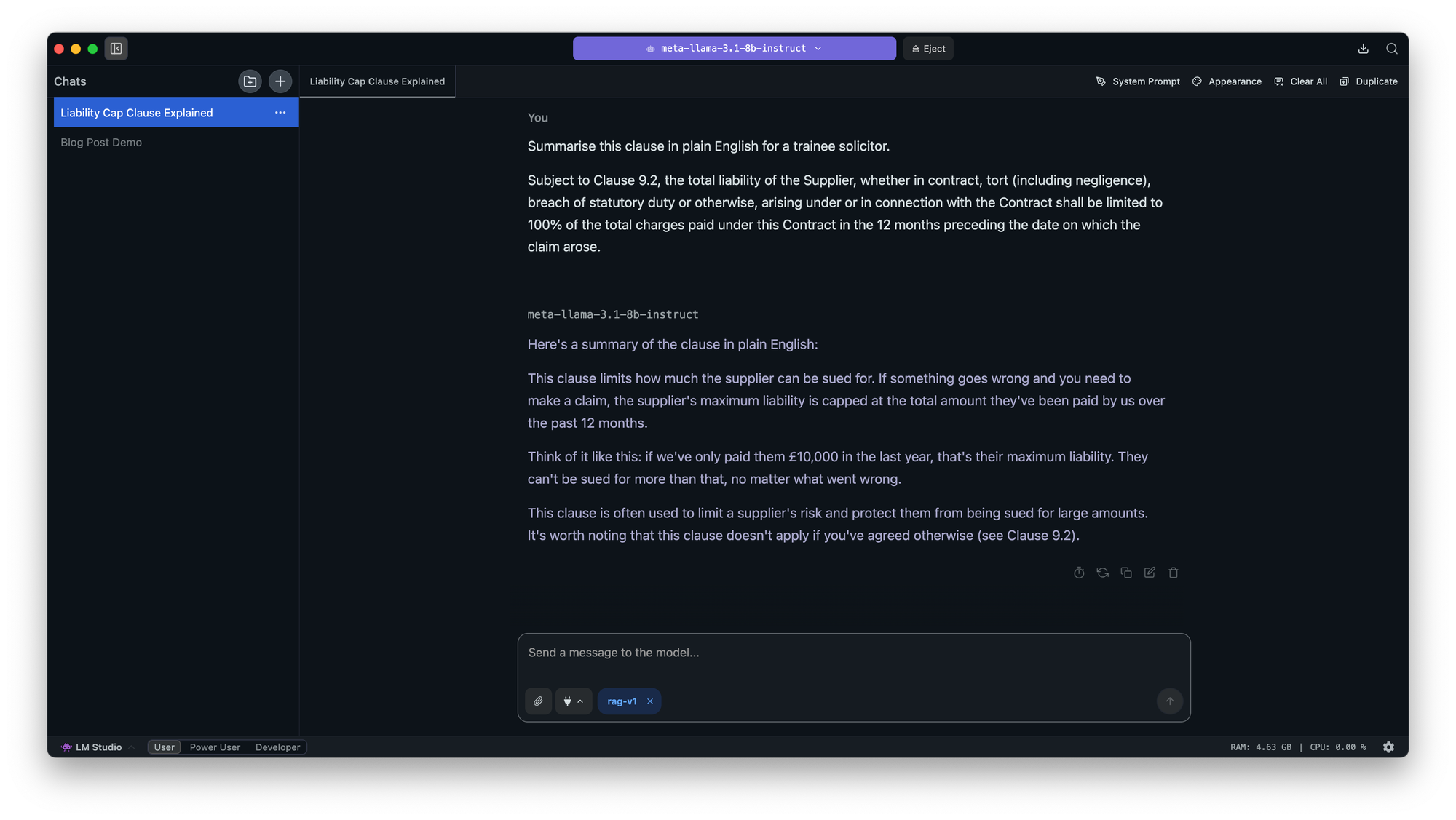
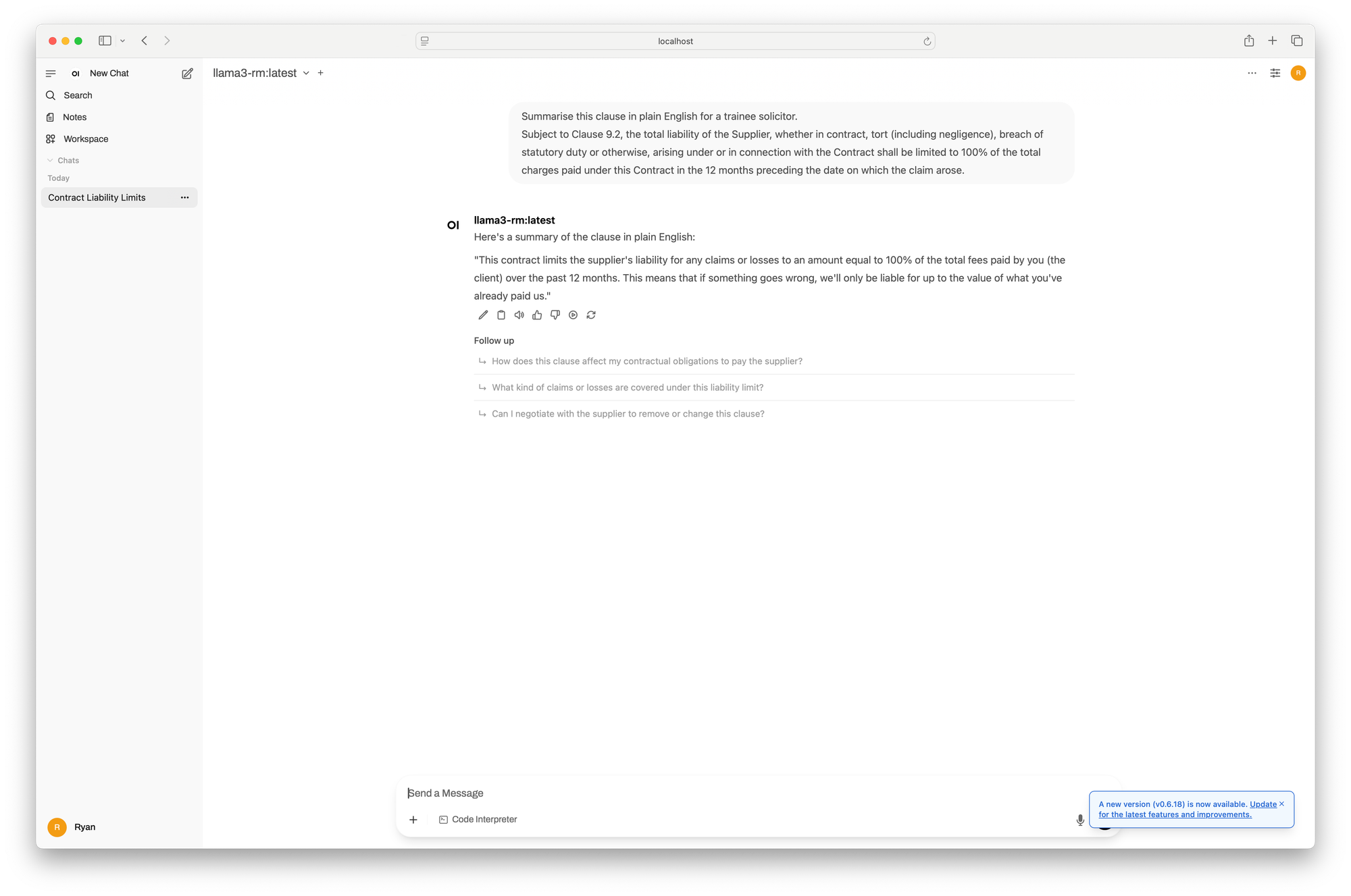
If you’re not technical, don’t worry, tools like LM Studio make this simple. You can experiment with clause summaries, redline comparisons, plain-language rewrites, or ask it to extract dates and obligations from a PDF. Another cool thing is because LM Studio supports a range of models, you can try the same clause across different ones to see which performs best. That alone can teach you a lot about where AI helps, and where it still needs human oversight.
Can I run this on my work laptop?
Maybe (I almost sound like a laywer...). If you’re in a legal tech or innovation role, and can put together a clear case, you should be able to get LM Studio or OpenWebUI/Ollama approved for your work device, especially if you’re using mock data.
That said, even if the model runs offline, you should still check with risk or compliance:
- Does it touch any live client material?
- Is it accessing shared drives?
- Are logs being stored that contain sensitive data?
Offline doesn’t mean risk-free. For many teams, it’s easier and safer to run this locally on a personal machine, especially during early testing.
Use it as a playground. Try out ideas to really uxtnderstand how it behaves before introducing it into any formal workflow.
Want to go further? Get better hardware.
A basic laptop with 8GB or 16GB RAM is enough to get started with smaller models like Llama 3 8B or Mistral 7B. If you’re curious about heavier use, bigger models, longer documents, or multiple contexts open at once then you’ll want to upgrade.
32GB RAM is ideal. You can pick up a used machine for around £500, an older ThinkPad or Dell workstation does the trick. If you want something more polished and portable, a refurbished MacBook Air M3 with 24GB+ RAM costs closer to £1,000 but handles most setups nicely.
Run a whole ChatGPT rival, for free
LM Studio is great for one-off experiments or comparing how different models respond, but if you want something that feels more like a full product, you can go further.
With 16GB of RAM, you can run a complete ChatGPT alternative locally with no internet required. Tools like OpenWebUI, when paired with Ollama, give you a proper AI assistant interface: chat history, file upload, document search, and even web search plugins. It looks and behaves a lot like many legal tech platforms already on the market.
The key difference? You’re running it on your own machine, with full control over the models, the data, and the experience.
Here’s what that setup process looks like:
- Install Docker
- Download OpenWebUI
- Run it locally with one command
- Connect it to Ollama
- Choose a model like Llama 3 8B or Zephyr 7B
- Go
This setup gives you:
- A web app like ChatGPT
- File upload and document-aware chat
- Local data control
- Web search, MCP, tools, memory... the list goes on.
- A fast way to test legal AI with no vendor ties
What is a Quantised Model?
Now you’ll often see models described as 4-bit, 8-bit, or using terms like Q4_0 or Q8_0. That’s quantisation. Don't worry too much about it though.
In plain terms, it’s a way of making big models smaller and faster, by lowering precision slightly.
- Smaller size = less memory used
- Slight dip in output quality (but usually still very good)
- You get more model for your hardware
For example: with 16GB RAM, you might be able to run Llama 3 8B in Q4_0 format. Without quantisation, it might not load at all.
Start with Q4 if you want speed. Use Q8 if you’ve got more memory and want top quality.
Recommended Starter Models
| Model | Size | Good For | RAM Needed |
|---|---|---|---|
| Mistral 7B | 4-bit | Fast, well-rounded | 8–12GB |
| Llama 3 8B | 4-bit | Strong general understanding | 12–16GB |
| Zephyr 7B | 4-bit | Chat-optimised, legal-aware | 8–16GB |
| Phi-3 Mini | 4-bit | Tiny and very fast, fun to test | 6–8GB |
| Llama 3 13B | 4-bit | Richer output, more nuance | 24GB+ |
Start Simple, Then Guide the Model
Start with simple tasks to get a sense of how the model handles legal content:
- "Summarise this clause in plain English for a trainee solicitor."
- "Highlight any key dates and obligations in this paragraph."
- "Rewrite this for clarity, preserve the legal meaning."
Then start pushing further:
- "Which version of this clause is more favourable to the buyer, and why?"
- "What’s risky or ambiguous in this NDA clause, and how might it be challenged?"
- "Compare these two engagement letters and tell me what’s missing from the second one."
This is where tools like OpenWebUI come into play. On their own, language models don’t remember anything between sessions, they respond to the prompt, and that’s it. With something like OpenWebUI, you can layer memory on top: setting preferences, saving conversations, guiding tone and format over time.
You’re not changing the model, you’re building a more useful system around it. Those extra layers is what turns a raw model into something closer to a reliable assistant. The prompts get better, the responses feel more consistent, and suddenly you’ve got something that starts to fit how you work.
A Quick Word From Our Sponsors: The Risk Team
Just because something runs on your machine doesn’t mean it’s free of risk. This is especially important in legal environments where confidentiality, data security, and regulatory compliance are non-negotiable.
Running local AI models gives you more control—but it also puts more responsibility on you. There’s no vendor in the loop catching mistakes, and no automatic protections if you accidentally feed it sensitive content.
So, before you start testing, it’s worth noting the basics:
• Don’t download random models from unknown sources.
• Avoid anything that exposes ports without knowing why.
• Keep Docker, Ollama, and other tools fully updated.
• Unless Risk has signed it off, stick to mock data or public templates.
Running local is a great way to explore AI’s potential, but only if you treat it with the same care as any other tool in your workflow.
I’d really encourage playing around with smaller models and seeing what they can do. You might be surprised how useful they are.
The people best placed to figure out what works are the ones closest to the work. You know the documents, the red flags, the language that actually matters, all of which makes you the best person to test and tune these tools.
Once you start finding what works, even if it’s rough, you can bring that insight into conversations with vendors, or with your own team building internal tools. You’re not just learning the tech, you’re helping shape how it gets used.
Run one model. Play with one idea. That’s all it takes to get started.