The Missing Layer in Legal AI: Control, Cost, and Accountability
There’s a rather big tension building that most firms haven’t fully addressed yet.
Clients expect legal costs to come down as AI becomes more embedded in delivery, yet the cost of using that AI, particularly at the frontier end, isn’t behaving like a simple downward curve. In some cases it’s stabilising, in others it’s becoming more variable, and in a few areas it’s starting to look like pricing is tied less to compute and more to dependency.
That creates a problem that tooling alone doesn’t solve.
This Isn’t About Capability Anymore
For the past few years, legal AI has been framed as a capability question. Which model performs best, which vendor to use, how to integrate it into workflows.
That framing worked when the goal was to generate language or extract information more quickly.
Once you introduce agents and multi-step workflows, the problem changes. You’re no longer asking whether a model can do the work, you’re deciding how that work gets done, at what cost, under what constraints, and with what level of risk.
That decision point is where most firms still have a gap.
The Missing Layer
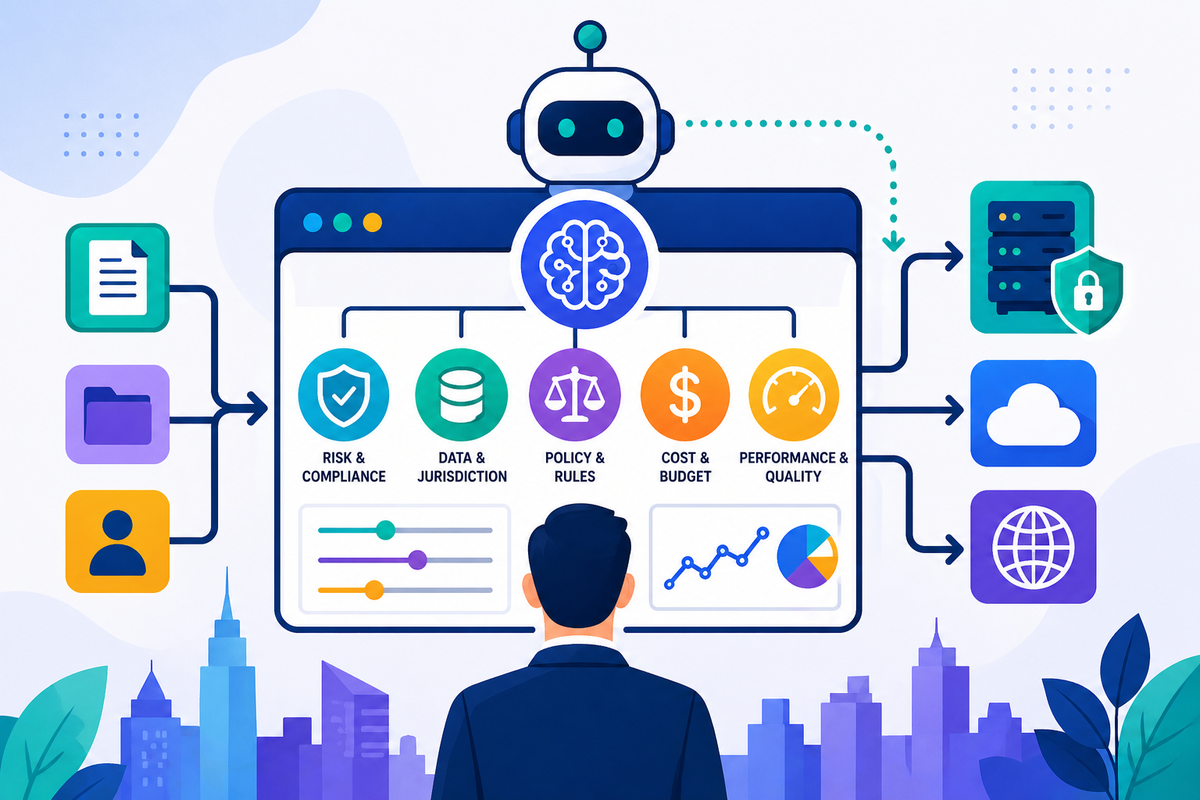
Most firms operate on top of vendor-defined systems where a task is submitted and an output is returned, sometimes with light configuration around prompts or templates. What sits in the middle is largely opaque.
That middle layer determines:
- which model is used
- where it runs
- how data is handled
- how much is spent to complete the task
- what happens when the process starts to drift
When that logic lives entirely inside a vendor tool, firms are not just consuming AI capability, they are handing over the decision-making that governs how it is applied.
That’s manageable at low volume. It becomes a risk when AI starts to underpin delivery.
Agentic Workflows Expose the Problem
As soon as work moves beyond a single prompt into a sequence of steps, the absence of control becomes visible.
Similar matters begin to produce different outputs. Costs vary in ways that are difficult to predict. Data handling becomes harder to reason about. Explaining why a particular outcome was reached becomes increasingly uncomfortable.
These aren’t edge cases. They’re natural consequences of letting execution logic sit outside the firm.
The Cost Assumption Needs Reconsidering
There’s an implicit belief that AI costs will continue to fall to the point where they become negligible.
That may hold for some categories of work, particularly where smaller models are sufficient. It is less clear for tasks that rely on frontier capability, where pricing is already starting to reflect performance, latency, and reliability rather than raw token usage.
A more realistic outlook is that costs will diverge:
- low-cost models for high-volume, structured tasks
- higher-cost models for complex reasoning and edge cases
At the same time, switching costs increase as workflows become embedded, which limits a firm’s ability to respond if pricing shifts.
This is where the problem becomes operational rather than theoretical.
When Client Expectations Meet AI Reality
Clients will expect efficiency gains to translate into lower fees or more predictable pricing.
If the underlying AI costs are volatile or trending upwards in certain areas, firms are left absorbing that difference unless they actively manage it.
Take a fixed-fee contract review process:
- £10 AI budget per contract
- multi-step workflow involving extraction and analysis
Partway through execution:
- half the budget consumed
- only a fraction of the work complete
Without a control layer, the system continues and the margin disappears quietly.
With a control layer, the system can intervene:
- switch to a cheaper model for remaining steps
- reduce scope where appropriate
- pause and escalate
This is less about optimisation and more about protecting the economics of delivery.
What the Control Layer Actually Does
This layer is not another interface or a more complex prompt. It’s a decision engine that sits in front of and alongside execution.
It evaluates each task using structured inputs, including:
- task complexity and type
- data sensitivity and jurisdiction
- budget constraints
- progress against that budget
- risk tolerance based on output use
Those inputs are combined to determine how the task should be executed, not just whether it should be executed.
A firm might define a rule that all AI processing must remain within the EU. That’s clear and defensible, but if a research task involves only public data, and an equivalent model outside the EU is significantly cheaper, then the rule starts to look inefficient.
A control layer treats that rule as an input, not a conclusion. It evaluates the context, weighs the trade-offs, and either selects the appropriate path or escalates the decision.
That’s closer to how legal judgement actually works.
The Practical Constraint Most Firms Face
Many firms don’t have multiple models or providers available. They have a single vendor platform.
In that context, the control layer still has value, but it behaves differently.
It can:
- gate what tasks are allowed to use the tool
- enforce data and jurisdiction rules
- standardise workflows to reduce variability
- apply budget thresholds before execution
What it cannot do effectively is optimise across multiple execution paths if only one exists.
That’s an important limitation, as without optionality, routing becomes approval rather than orchestration.
Where Firms Will Actually Differentiate
Model performance will continue to improve and converge, so the advantage of choosing one provider over another will narrow over time.
The more durable advantage lies in how firms encode their own judgement into the systems that orchestrate those models.
That includes:
- defining how cost, accuracy, and speed are balanced in practice
- ensuring consistent handling of similar matters
- maintaining visibility into how outputs are produced
- retaining the ability to adapt when cost or capability shifts
In regulated environments, the ability to explain those decisions is as important as the outcome itself.
Policy Isn’t Enough
Most firms already have AI policies covering data use, approved tools, and general principles.
Those policies are necessary, but they don’t execute.
They don’t adjust behaviour mid-task, they don’t track cost in real time, and they don’t resolve trade-offs as conditions change.
If governance only exists as documentation, it has limited impact on how systems behave in practice.
How Firms Can Start to Approach This
This doesn’t require a full rebuild or a multi-year transformation programme. Most firms can start introducing control without replacing their existing tools, but it does require being deliberate about where decisions are made.
The first step is to separate the idea of using AI from deciding how AI is used. Even if there is only a single vendor in place, you can begin by introducing a lightweight layer in front of it that classifies tasks before they are executed.
At a minimum, that means capturing a small set of structured inputs alongside the prompt:
- what type of task this is
- whether the data is sensitive or restricted
- any jurisdictional constraints
- an expected budget or cost range
- how the output will be used
That information doesn’t need to be perfect. It just needs to exist. Without it, every task is treated the same, which is where inconsistency and cost drift begin.
From there, firms can start to introduce simple routing rules. Not complex orchestration, just clear decisions about when the vendor tool should be used and when it shouldn’t. In many cases, this will initially act as a gate rather than a router, but even that changes behaviour.
The next step is to make cost visible at the workflow level. Most tools don’t expose this in a way that’s useful during execution, so firms need to approximate it. Define expected cost per task, track usage across steps, and introduce points where the process can pause if it starts to drift.
Even rough visibility is enough to force better decisions.
Over time, the layer becomes more useful as optionality increases. Introducing a second model, a local capability, or even a simplified fallback path allows the system to make real trade-offs rather than simply approving or rejecting tasks.
None of this needs to be perfect from day one. The objective is not to build an optimal system upfront, it’s to stop decisions being made implicitly inside tools you don’t control.
Once that layer exists, it can evolve. Without it, there’s nothing to evolve.
Legal AI started as a question of whether models could do useful work. In many areas, that question has been answered.
The more pressing question now is control, as in who decides how that capability is applied, how costs are managed, and how those decisions are made consistent and defensible over time.
If that responsibility remains with the vendor, firms are not fully adopting AI. They are operating within someone else’s decision framework.
As agents become more capable and more embedded in delivery, that distinction becomes harder to ignore.